



Ai2 Launches SciArena, a ChatBot Arena–Inspired Platform to Benchmark AI for Science
Initial findings crown OpenAI’s o3 as the top performer, especially in technical fields like engineering


Nonprofit AI lab Ai2 has launched a new platform to help researchers evaluate which AI models perform best on scientific literature tasks. Called SciArena, it’s an open, collaborative service that enables head-to-head comparisons of large language models. Think ChatBot Arena—but built for the scientific research community.
“Measuring progress in using AI agents for literature-grounded scientific discovery is challenging,” Arman Cohan, an AI2A research scientist and a Yale University assistant professor of computer science, tells me. “Traditional evaluation benchmarks and methods fail to capture the nuanced, domain-specific requirements of scientific literature tasks, especially in fast-evolving fields. SciArena aims to address this gap by providing an open, crowdsourced platform for continuous evaluation of LLM agents in science.”
Which LLM Is Best for Scientific Tasks?
To start, SciArena currently hosts 13 proprietary and 10 open-source models, each one chosen for their representation of current state-of-the-art capabilities. These include OpenAI’s o3, o4-mini, and GPT-4.1, Google’s Gemini 2.5 Pro and Flash variants, Anthropic’s Claude 4 Opus/Sonnet series, DeepSeek’s R1, Meta’s Llama 4 variants, and Alibaba’s Qwen3 series.
Over 13,000 votes were tallied from more than 100 researchers across different scientific fields to compile the first evaluations. However, to ensure the reliability of its findings, Ai2 employed a rigorous quality control process for its pairwise model comparisons. All of the initial evaluators had at least two peer-reviewed publications and prior experience with AI-assisted literature tools. They also participated in a one-hour training session.
But what happens now that the tool is live? Ai2 says SciArena utilizes blind rating, meaning the models used to generate responses will not be revealed until after a user casts their vote. And when considering data reliability, it’ll factor in two things: inter-annotator agreement (IAA)—how much different experts agree when evaluating the same material—and self-consistency—how consistent a single annotator is when rating similar or repeated tasks over time.
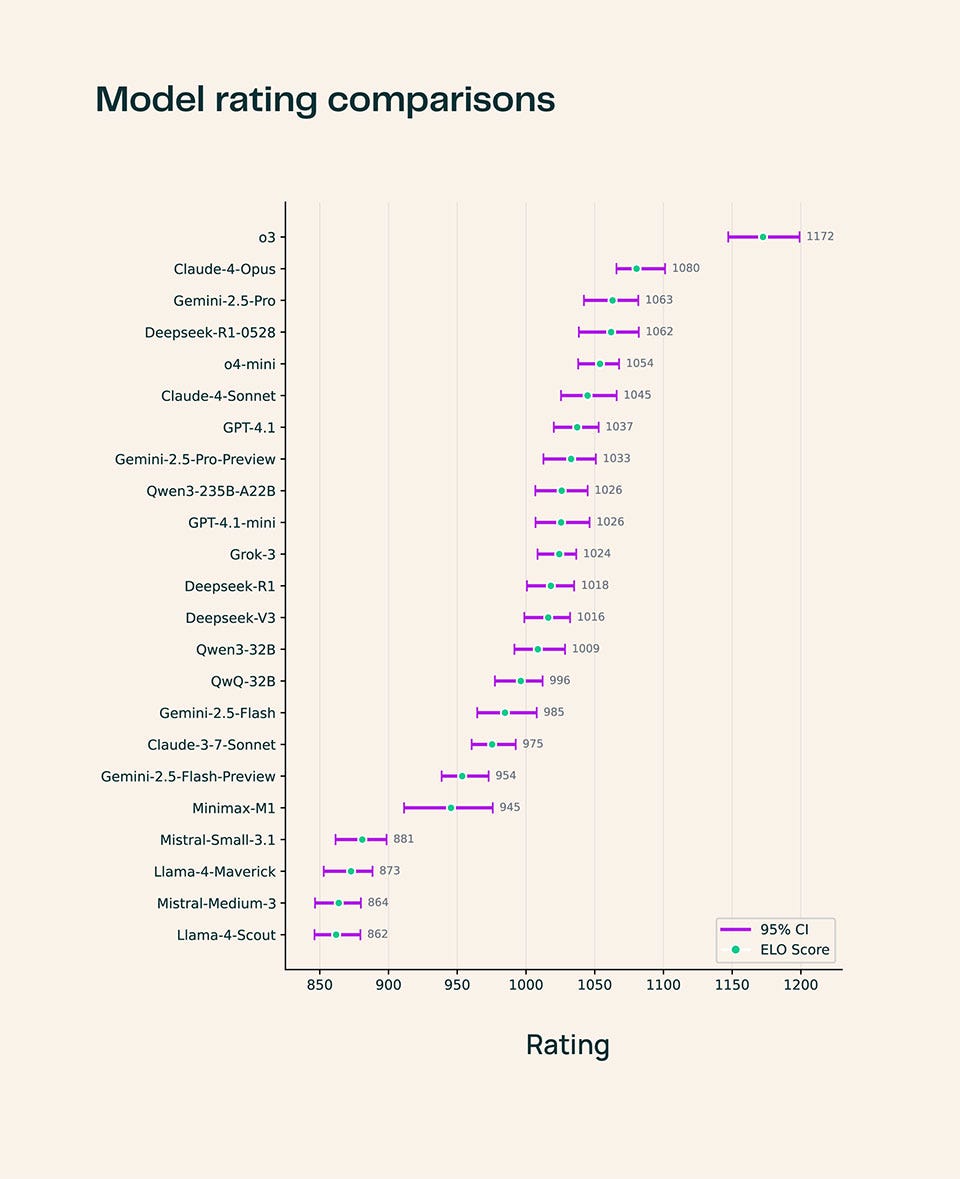
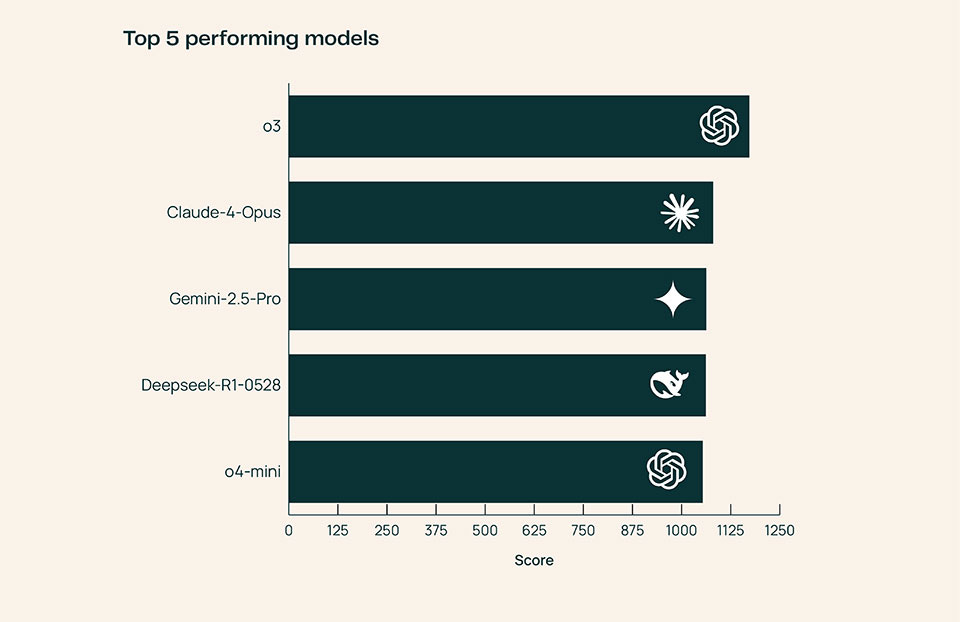
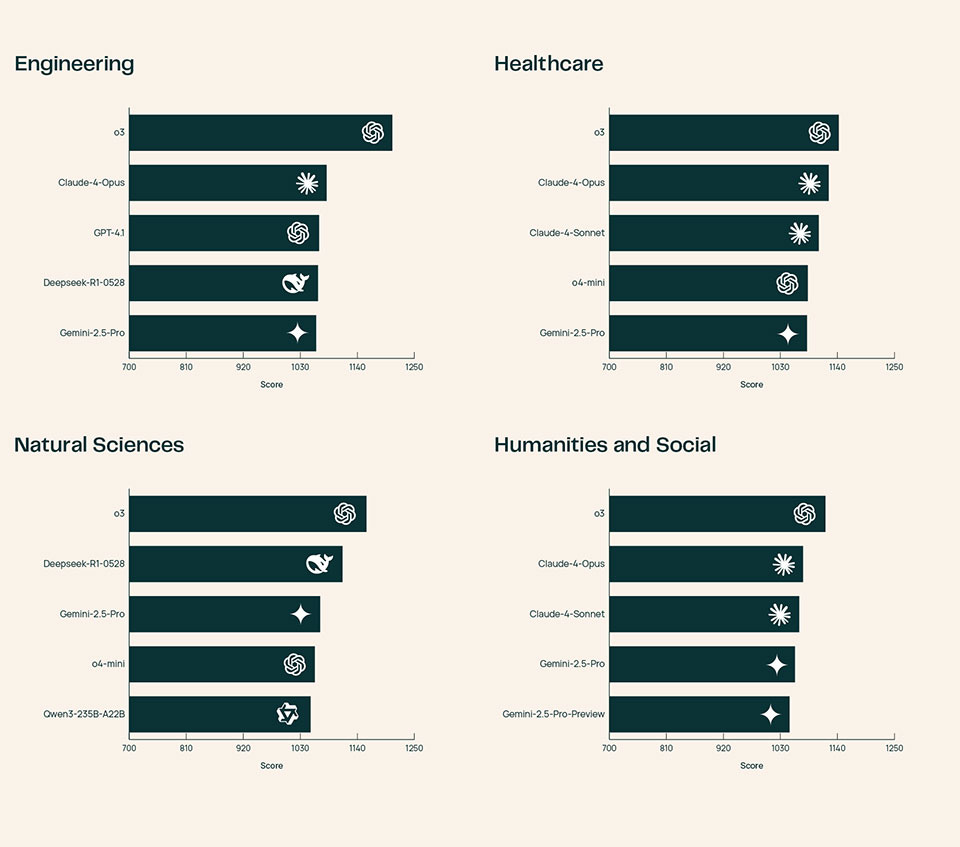
After tabulating the 13,000 votes, Ai2 reveals that OpenAI’s o3 consistently outperforms its peers across all scientific domains, provides the “most detailed elaboration” of cited scientific papers, and generates more technical outputs in the field of Engineering.
As for the remaining 22 models, SciArena found that performance levels would vary by discipline. For example, Anthropic’s Claude 4 Opus excels in Healthcare, while DeepSeek’s R1-0528 did well in Natural Science. While the platform initially supports 23 models, plans are in place to add new models in the future.
“Ai2 has a long history of delivering tools to help scientists—from the Semantic Scholar website, which is nine years old and serves millions of users every month, to Paper Finder and ScholarQA, two LLM-powered tools we released earlier this year,” Doug Downey, Ai2’s senior director of semantic scholar research, explains. “One of the most difficult challenges we and the broader AI for Science community face today is evaluation. How do we measure whether our tools are helping scientists, and which ones are most effective? With SciArena, we’re enlisting the community to help with this evaluation challenge. We hope SciArena provides more reliable and democratic evaluation of AI for Science, and helps point the field toward the most important unsolved problems.”
ChatBot Arena But For Science
There are three parts to SciArena: The first is the core platform, where researchers submit questions, view side-by-side responses from different models, and vote on their preferred output. Next, a leaderboard displays the top models using an Elo rating system, based on community votes. Lastly, there is a custom evaluation benchmark called SciArena-Eval that assesses the accuracy of model-based evaluation systems.
When asked what advantage SciArena-Eval has over other scientific AI benchmarks, Arman shares that, unlike current methods, which rely on using other strong LLMs as judges to evaluate a model’s output, Ai2’s solution is “the first benchmark designed to assess model-based evaluators in judging literature-grounded responses to user questions.”
In addition, it “uses expert human preferences from researchers as ground truth. Even the top-performing model in our experiments, o3, achieves…65.1 percent accuracy in predicting human preferences. This reveals a critical insight: While automated evaluation using LLMs might work relatively well for general tasks, as shown by other works, scientific literature tasks require a level of expertise and nuance that current AI evaluators struggle to capture.”
Ultimately, the AI lab aims for SciArena to accomplish two key objectives: to help researchers make more informed decisions about which AI tools to use for their specific needs, and to democratize the actual evaluation process, a system Arman describes as one “that captures the collective judgment of the entire scientific community for reliable and up-to-date evaluations. It’s essentially applying the peer review principle to AI evaluation, creating a living benchmark that evolves with science itself.”
Downey puts it this way: SciArena “aims to provide live, community-led evaluation of AI—as in ChatBot Arena, but specialized for science.” While ChatBot Arena may focus on general conversation, SciArena takes on more technical questions. “They require synthesizing multiple scientific papers to answer a question,” he elaborates. “By analyzing questions and votes from the community, we hope to shed light on which models are best on this important task and for what reasons. Does the winning model identify the most salient points from the source material, or does it just employ a style that users appreciate? These are the kinds of questions we’d like to answer as we acquire more data. In the future, we’d like to broaden the tool beyond literature-focused questions to evaluate AI support across other parts of the scientific workflow—ideation, running experiments, analyzing data.”