

Why Ai2’s SERA Could Change How Software Gets Written
The first of the nonprofit AI lab's new open coding agents is built to tackle private code, streamline workflows, and match top-tier models


Coding agents are everywhere. What was once a handful of experimental tools has become a crowded field spanning GitHub (Copilot), OpenAI (Codex), Google (Jules), Anthropic (Claude Code), AWS (Kiro), Vercel (v0), Salesforce (Agentforce Vibes), and a growing roster of startups, each promising to change how software gets written. Now, nonprofit AI lab Ai2 is entering the fray, launching a family of open-source coding agents led by its first release, SERA, that it says outperforms Qwen 3 30B in context lengths and matches the performance of state-of-the-art smaller models such as ones from Devstral.
Despite the rise of vibe coding, Ai2 argues that most coding agents still share three fundamental limitations: they’re closed, expensive to train, and ill-suited for private codebases. To counter this, SERA is an open-coding agent model that can be trained on individual repositories, allowing it to specialize without being weighed down by irrelevant or generic data. But while it does vibe coding, Ai2 thinks it’s much more than that.
“I think it’s a very good colloquial term for what we’re doing, but I think it also underrepresents a little bit the scale and potential of coding agents,” Ethan Shen, SERA’s project lead, tells The AI Economy in an interview. Coding agents, he says, are “very highly impactful in their own right—you have AI models that can do these real-world tasks…but beyond that, it’s a very good proxy for a lot of other agent tasks that we don’t really know how to solve yet.”
Developers and researchers interested in SERA can download not only the agent, but also the models, training recipes, and its Claude Code integration (using a pip package) from Hugging Face. SERA can also be launched with a single line of code, making it accessible to those with no prior knowledge or training in language models.
SERA’s Origin Story
The creation of SERA appeared to happen by accident. Shen, a doctoral student at the University of Washington, and his research team of three, were experimenting with coding agents and discovered that “a lot of existing data generation strategies for coding agents were very cumbersome, hard for us to implement.” His team set off to eliminate or loosen constraints and requirements, such as unit testing, in the process. “What’s the easiest way to generate data so that we can experiment at scale?” he asks.
He acknowledges that what his team did is “counterintuitive,” since most traditional machine learning and software engineers believe that high-quality, thoroughly verified, and correct data is required for training reliable models, and that things such as unit testing and rigorous validation can ensure that coding agents produce functional, bug-free results.
As it turns out, the team’s work proved fruitful, generating state-of-the-art performance in benchmarks. From there, Shen explains, came the realization: “If you can do data from any repository, then you can not only explore scaling, which is super important with AI. No one’s really studied coding agents at massive data scales. Not only that, but we can now also explore specialization…You can run data ablations to see what really matters. We found a lot of very interesting things about common practices in data curation or coding agents that we find actually hurt performance, or there are other things that help performance a lot.”
Initially, the team considered splitting the coding agent’s tasks—such as code searching and editing—among specialized models to yield better results. However, through trial and error, they discovered that a single, unified model could handle every workflow step just as well while also simplifying development and data generation and making them more scalable. “It was a very windy path, a lot of data experiments, [and] a lot of frustration,” Shen reveals. “But once we realized that…we could strip away a lot of unnecessary details, we realized that we could do a lot with it, and that led to [SERA].”
What’s in a Name?
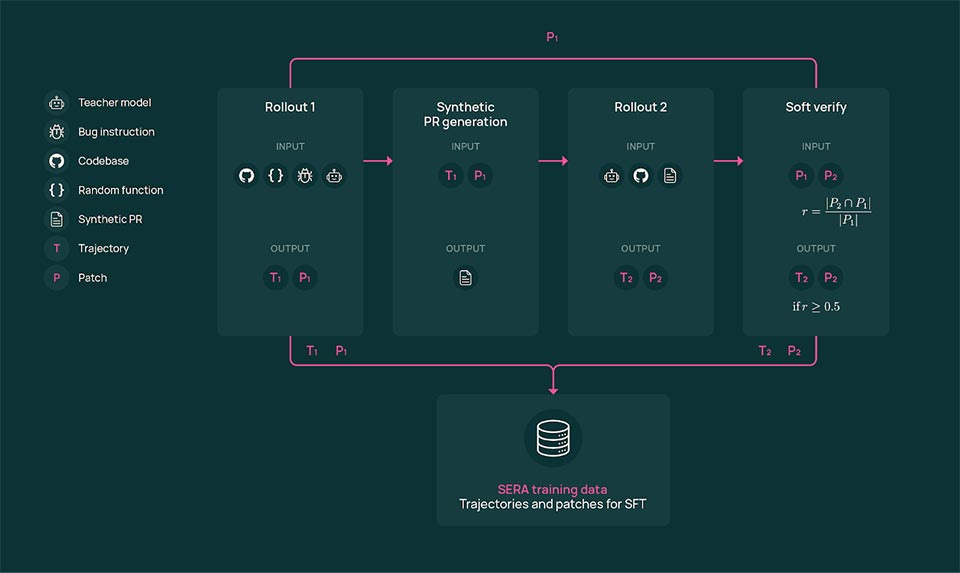
The name SERA is more than branding. Short for soft-verified Efficient Repository Agents, it captures Ai2’s approach. Typically, when training coding agents, many synthetic examples are generated in which the model sees bad code evolve into better code. Those fixes have to be fully tested and proven correct—what’s known as “hard-verified”—which can be a costly and tedious process.
However, Shen’s team concluded that fixes didn’t need to be perfect in order for the model to learn—any step in the right direction would be helpful. To that end, Ai2 opted to embrace partially correct fixes—this is “soft-verified”—which results in better infrastructure, faster scaling, and the same level of performance compared to fully verified data.
By adopting soft-verified generation, Ai2 says it can cut costs, making SERA more palatable for all-caliber software developers.
SERA Unveiled: An Open-Source Agent for Code
“We believe that one huge advantage of coding agents that hasn’t been fully realized yet is the ability to specialize a coding agent to your own code base,” Shen says. According to him, no matter the model—Claude Code or a large open-source option from GLM or Qwen, for example—they’re all trained on general datasets. That leaves a gap for organizations with private codebases that can’t be shared with APIs or aren’t willing to bear the cost of self-hosting. The result: Developers are left asking, “How do I get a coding agent that’s specific to my use cases, to my workflow, to my infrastructure?”
For large enterprises like Amazon and Google, it’s easy for them to train coding agents on their specialized environments. They have the resources. But what about small- to mid-sized businesses? This is an opportunity Shen believes is right for SERA: “How can you train a specialized coding model on your own code base and do it cheaply, do it on a small, open-source model, and be able to outperform the teacher model that you use?”
Here’s how…
SERA is available in two sizes, with 8 billion or 32 billion parameters, and is built on Qwen3 with 32K context length. Shen points out that these can be deployed freely and run on a consumer GPU. Notably, Ai2’s own models aren’t used to build these SERA variants, nor do they serve as its “teacher” model. By choosing open-source models to train SERA, it saved money because closed-model API usage can be prohibitively expensive and lead to other issues. “You don’t know what you’re really getting,” he clarifies. “They throttle the API, use a weaker model sometimes. There are a lot of factors there, and it’s just expensive to use. We tried it first, and it costs thousands of dollars to just get a small bump in performance.”
When asked about choosing GLM over Olmo, Shen remarks that although the latter is a “great model” suitable for general-purpose tasks, coding agents require a “specialized teacher model, specialized just for that task, which GLM has focused on—that’s been their main focus for a while now. So, from a perspective of what’s a strong feature model that we can pick that we know…we can distill high-quality data from in the coding agent space, the GLM models made the most sense.” However, he says that coding agents could be incorporated into Olmo later on.
With GLM-4.5-Air, practitioners have a more affordable and manageable teacher model at their disposal. While it requires at least four GPUs to deploy fully, it’s something achievable for university labs, smaller research facilities, and the “occasional practitioner.”

But what does it mean to have a specialized agent? What specifically is SERA trained to do? Shen explains that it can solve pull request (PR) issues. Can the bot troubleshoot why there’s a problem with your repository after looking at the error log? He posits that in the future, Ai2’s coding agent may compete in the same arena as Lovable, helping developers handle end-to-end tasks such as web app development, though for the immediate term, it’s about fixing bugs.
As for benchmarking, Ai2 reports that SERA performs “competitively” with leading open-coding agents, such as Qwen3 Coder. Shen shares that when training on general repositories, SERA outperforms both Qwen3’s 30B model with 32K context length and its 64K context length “by a lot.”
“We stack up pretty well,” he proclaims.

SERA also performs just as well as Devstral-Small-2 and GLM-4.5-Air on SWE-Bench Verified.
Ai2 expects its new coding agent to be used for various use cases, from personal to work projects. That said, Shen believes SERA has more realistic value in the enterprise: ”That’s where enterprise code bases are just huge, so you have so much data you can specialize on.” Ultimately, he hopes this project will create a “strong pipeline for people to generate massive amounts of data from” and that SERA will be helpful to people across the tech industry.
And while SERA is Ai2’s first coding agent, the team hasn’t had time to think about what’s next. However, Shen discloses that one possible area is developing long-context bots, agents that can handle very long sequences of actions or information. Another option is looking into Reinforcement Learning for coding. “There are a lot of directions that we’re thinking about taking this. We haven’t fully fleshed out a roadmap yet, but that will probably be figured out in the near future,” he states.
The private codebase specialization angle is smart. Most coding agents are trained on public repos and fail hard when they hit internal codebases with domain-specific patterns. SERA's "soft-verified" training approach is interesting—accepting partial fixes instead of requiring full verification should make it way easier to bootstrap on custom code. But I'm skeptical about the 8B/32B parameter sizes competing with Claude/GPT level models on complex architectural decisions. Small models can handle tactical code completion, but strategic refactoring and system design still need the big guns. The real test: can SERA maintain context across multi-file changes in a 50k+ line codebase? That's where most coding agents break down, regardless of parameter count.