

Train Together, Share Nothing: Ai2’s FlexOlmo Framework
A privacy-first approach to building collaborative AI models without centralized data pooling

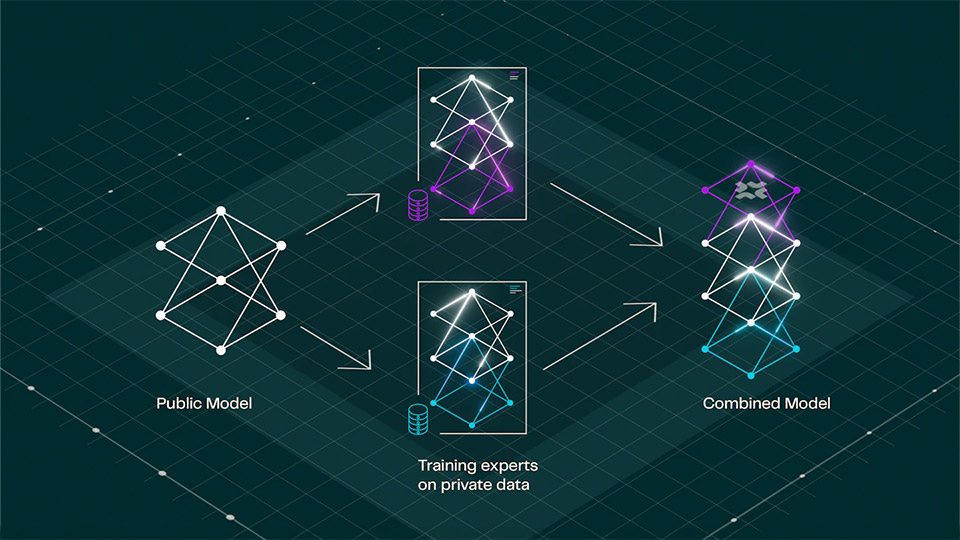
Ai2 has unveiled FlexOlmo, a new framework that lets multiple organizations jointly develop language models without requiring centralized data pooling. Ideal for those in regulated industries, it provides developers with granular control over how and when their data influences the model, addressing long-standing concerns regarding privacy, IP protection, and data sovereignty in collaborative AI projects.
Imagine a group of pharmaceutical companies partnering to develop a large language model (LLM) to help with drug discovery, clinical trial analysis, or prescribing guidance. To make it work, a large dataset is needed. Unfortunately, HIPAA and privacy laws, as well as corporate policies, prohibit these entities from sharing data. Working alone is an option, but the more information a model has, the more accurate the outputs will be.
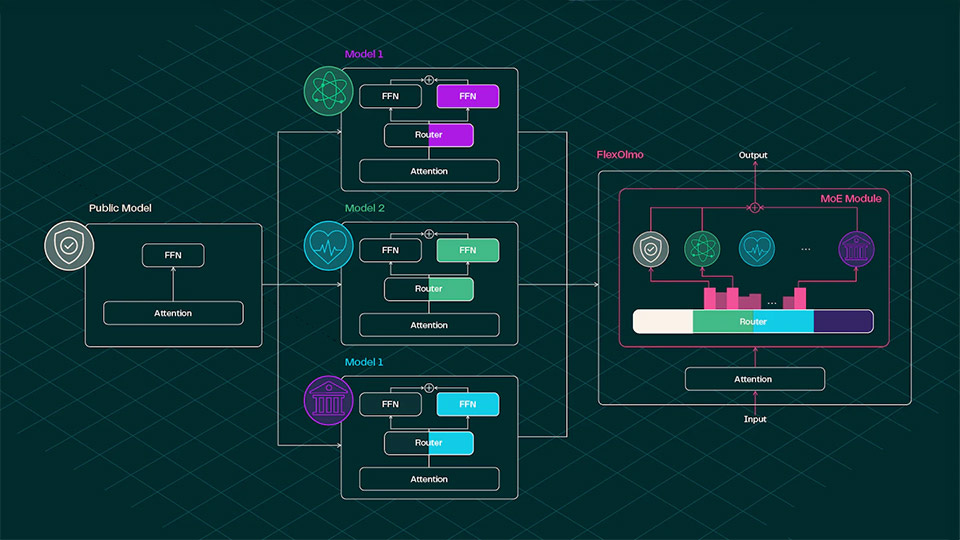
To solve this, FlexOlmo uses a mixture-of-experts (MoE) approach. Each organization trains a specialized expert module locally using its private dataset. These modules are later integrated into a shared model, enabling collective performance gains without surrendering proprietary information. In other words, FlexOlmo is enabling cross-silo federated learning. Data owners retain the right to opt in and opt out during inference. The AI non-profit lab claims that FlexOlmo’s design not only allows organizations to contribute “asynchronously without sharing their private data,” but also supports future updates with new data and provides a “strong guarantee” for data opt-out.
This framework “is specifically designed to address the unique challenges of our setting: merging models that have been pre-trained on entirely disjointed datasets with differing distributions,” Ai2 writes in a blog post. “We show that prior model merging techniques struggle in this scenario, whereas FlexOlmo is able to handle it effectively.”
In early experiments, FlexOlmo reportedly achieved performance “very close” to a hypothetical model trained on all combined public and private data. However, it does not appear that Ai2 has done a real-world model comparison so far.
Ai2 also acknowledges concerns around data leakage or replication, a common fear in collaborative AI systems. In internal tests simulating extraction attacks, the team found that only 0.7 percent of training data could be recovered from overtrained models. This suggests that FlexOlmo makes it difficult to retrieve any meaningful amount of original data. For organizations seeking additional protection, Ai2 recommends training expert modules using an alternative approach: differentially private learning. This provides formal privacy guarantees without altering the overall architecture.
With AI model makers scouring every part of the internet for available data, companies are becoming increasingly protective of their information. They don’t want it to benefit anyone else but themselves. But at the same time, some of them have to work collectively to achieve the greater good. Still, that doesn’t mean they must freely surrender their data.
For Ai2, FlexOlmo adds to its expanding suite of open-source tools aimed at making AI development more accessible, transparent, and modular. While the lab’s roots are in open science, it’s increasingly building frameworks and forming partnerships to serve the needs of enterprise users. FlexOlmo is well-suited for organizations in regulated industries, and its recent partnership with Cirrascale, which makes Ai2’s LLMs available via cloud infrastructure, signals a broader move towards enterprise-grade deployments.
Companies interested in FlexOlmo should reach out to Ai2 to be one of the first partners to try it out.