

Microsoft Rebuilt Search for a Customer That Can't Click
Twenty years of ranking ran on human behavior. Web IQ replaces it by asking AI models directly what they want.


Search engines learned what a good result looked like by observing how people behaved. A click followed by a long page stay signaled satisfaction, while a quick bounce back to the search results signaled a miss. Microsoft built its Bing search engine on those patterns. But in the AI era, there’s a type of user that can’t click: agents. That led the company to try something that sounds strange: interviewing the AI.
“We’ve been interviewing the agent,” Tim Frank, Microsoft’s corporate vice president for monetization, commerce, and the AI economy, told The AI Economy on the sidelines of this year’s Build conference. “What did you like of this answer? How would you like it different for you?” The AIs’ response? They want structured answers, tight token budgets, speed for follow-up calls, and disclosure of how deep the search went. Those preferences, not what we humans do, are what Microsoft’s new Web IQ service is built to satisfy.
Introduced at Build, Web IQ is a set of grounding APIs built for agents. The service supplies AI systems with real-time context pulled from across the web, spanning webpages, news, images, and videos. It’s designed to help agents not only surface the right information but also convert it into useful evidence and apply it to their reasoning. It’s the latest addition to Microsoft’s line of IQ products, joining Work IQ, Fabric IQ, and Foundry IQ.
For developers, Web IQ isn’t replacing the model underneath an agent. It’s intended to complement the LLM, but addressing two things no model can fix on its own. First, a model’s knowledge stops at its training cutoff, so it knows nothing about what happened after. And second, because a model can only hold so much, the long tail of obscure detail never makes it in.
“Microsoft is one of a very small number of companies that has invested in the infrastructure to build an index of the web, and then to make a retrieval layer that says, ‘I heard what you wanted, let me give you back—not the whole internet—the slice of what’s useful based on what you told me,’” Frank said. “It’s a very technically challenging thing to build, which is why you don’t see tons of people doing it.”
Bing for AI Agents
The company calls Web IQ a “search engine for AI systems.” The description fits because Web IQ is less a new product than an extension of the Bing platform. It sits on the same global index Microsoft has refined for over two decades, relies on the same crawlers, and inherits the same rules of the road, from honoring robots.txt to enforcing publisher access controls.
Where the two diverge, however, is everything above the index. While Bing’s retrieval and ranking machinery was tuned for a person scanning a page of results, it was rebuilt in Web IQ for machines that read differently. When a human searches for something on the internet, they’re presented with the traditional results page featuring ten blue links. For agents, this isn’t the way.
“They don’t have a limit of ten [per page] because they don’t have a viewport on the screen,” Frank explained. “For the human, it’s quite important that you get the right answer in one of the first ten links. For the agent, you actually could give many more links because it’s not very expensive for the agent to consider 15 or 1,500 items. The cost is in how many tokens you give it. Then it needs to rationalize and understand the tokens and decide if it wants to make another call or not.”
Under the hood, Web IQ is itself built from AI models, just not the kind anyone chats with. Microsoft says it chose a handful of in-house models over a sprawl of specialized ones, each with a defined job: one converts web content into mathematical representations so the system can match meaning rather than keywords, while others read, rank, and select the passages worth handing to an agent. The telling detail is how they’re trained. Microsoft optimizes them not for standalone benchmark wins but for how their output performs inside another model’s reasoning. The practical effect is worth sitting with: a small set of Microsoft models now decides what evidence everyone else’s models get to reason over.
All that evidence comes from somewhere, which raises the question that publishers have been asking for two years: does letting an AI system touch your content mean it gets permanently absorbed into someone’s model? Frank said Web IQ doesn’t work that way. The licenses underpinning the service cover inference only, meaning a publisher’s content is fetched only when an agent needs it to answer a question, is used, and is traced back to its source, with nothing baked into a model. “None of these licenses are for model training,” Frank said. Anyone seeking content to train models, he added, has to strike deals outside of Web IQ’s scope.
Why did Microsoft release Web IQ when Bing Search API offered similar capabilities? Simply put: the now-retired developer tool wasn’t made for AI agents. It was designed for human use, Frank said, and delivered a human-style SERP experience. The company rebuilt it for the AI era and deliberately gave it a new name. “We needed to be able to cleanly break from the convention and decisions we made to optimize for a human [and] to make it work excellently for AI systems. The name is intentionally separate so people don’t confuse the stuff designed for humans versus what is explicitly designed for AI.”
Best in Class For Quality, Latency, Token Density
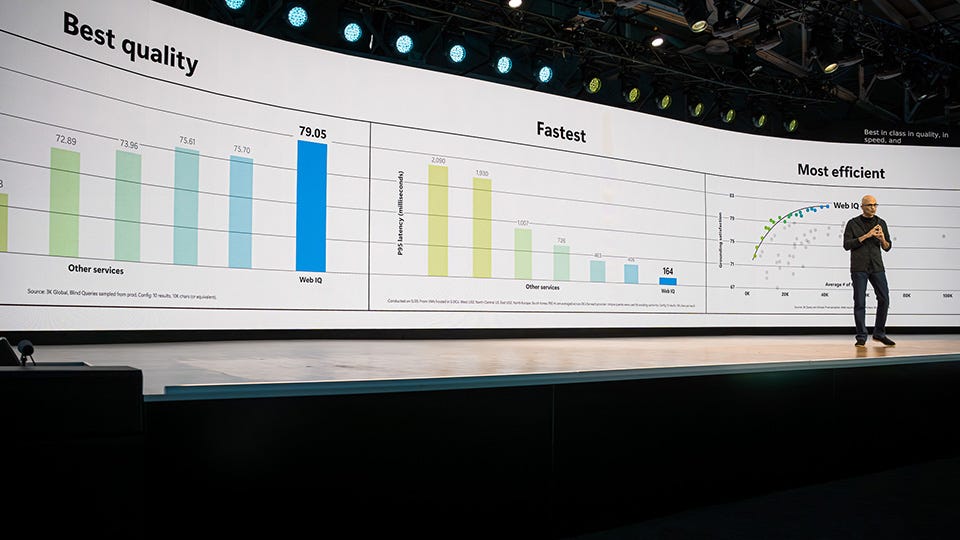
Microsoft claims Web IQ beats every rival on quality, speed, and token efficiency. “The company that’s number two on some of [the benchmarks] is not two on all of [them], so it’s not like there was a leader,” Frank said, claiming that before Web IQ, developers needed to decide between accuracy, speed, and efficiency. “Depending on which of those heuristics you would have chosen, you’d have to work with three different suppliers. For the first time, you can actually get all three best-in-class with one supplier that has 20 years of experience in this space.”
In an evaluation of grounding satisfaction, a metric that captures whether grounding actually meets user intent across completeness, freshness, and authority, Microsoft reported that Web IQ has a higher score than competitors. This means users trust its response and achieve stronger downstream outcomes.
Speed determines whether an agent can take multiple retrieval-and-reasoning steps or must cram everything into one attempt. Microsoft reported Web IQ returns responses in under a sixth of a second, nearly 2.5 times faster than its peers.
The last variable is token consumption, something many developers and organizations are concerned about today. Microsoft claimed that Web IQ can reduce the amount of context required to produce a “given level of quality” thanks to its use of passage-level evidence and its high information density per token.
It’s worth noting, though, that despite these claims, Microsoft doesn’t name the competitors it tested against. Moreover, these comparisons are ones the company ran itself.
Impact on Enterprises
Enterprises have spent the past two years carefully grounding their agents in clean internal data. Inviting the open web into that loop sounds like a step backward. Why would a company risk polluting trusted retrieval with the same stale pages and SEO-gamed content that made the web hard to trust in the first place?
“A lot of AI applications will want to have fresh, reliable, ground-truth data that they can rely on,” Frank said. He offered a shopping app as an example. Build one on today’s AI alone, and users will hit links to products that no longer exist. What developers want underneath it is a source of honest, current answers about availability, local pricing, and promotions. That, in Frank’s telling, is the kind of use case Web IQ exists to serve, and not only for apps built around a model.
Worth remembering: when Web IQ pulls from the web, it doesn’t dump the internet on an agent. It returns just the slice that’s useful, passages the agent can reason over and trace back to a source. That design targets AI’s most corrosive habit—the answer that sounds confident and turns out wrong. Frank said he’s been burned that way “many a time,” and that the stakes vary, with a wrong answer sometimes costing nothing but other times carrying real costs. Get tricked enough times, he said, and no amount of model improvement will win back the trust.
While Web IQ can be useful for consumers, when it’s part of the enterprise, it’s not intended to stand alone. As mentioned earlier, it’s part of the broader Microsoft IQ family. Frank used a Windows 11 upgrade to illustrate how the suite works together. For a consumer weighing a purchasing decision, Web IQ alone can surface official support details from Microsoft, corroboration from independent reviewers, and alternative comparisons. But when applying that same scenario to a CIO planning a company-wide upgrade cycle, one layer isn’t enough. Web IQ informs them about what’s currently supported and sold in the public marketplace, but Fabric IQ catalogs the hardware currently deployed in the company and Work IQ shows how heavily workers use it.
“As you start to bring all these different layers together, now you can stack that to make a really good business decision. That’s what’s special about delivering it through Azure and through the Microsoft IQ suite,” Frank said.
Web IQ is currently available to a limited group of enterprise customers, with priority given to those working with Microsoft’s account teams and “developing production AI workloads that require high-quality, current, real-world grounding.”
Disclosure: I attended Microsoft Build as a guest of the company, with my travel and expenses paid for. However, what I write reflects my own reporting and analysis. No one reviewed or approved this piece before publication.